What is a recommendation system?
A recommendation system is a system that predicts an individual’s preferred choices, based on available data. Recommendation systems are utilized in a variety of services, such as video streaming, online shopping, and social media. Typically, the system provides the recommendation to the users based on an item liked/disliked, or movies watched by a user.
Typically, a recommendation engine processes data through the following steps-
- Collect
- Store
- Analyze
- Filter
Types of recommendation systems
In this blog, we’re going to discuss a graph-based recommendation engine
In general recommendation systems work offline. A process passes each user’s history to a set of algos and generates recommendations once in a while as per business use case.
To understand the drawback of such a process, suppose a user searched for action movies and watched them, so typical offline systems recommend action movies when he will come next time. In this case, the system knows what a user is watching but not what he is about to watch and it can’t accommodate this new knowledge.
As a result, its subsequent results will not be interesting and the user is going to ignore them.
Graph databases- The Saviour!!
Before talking about a graph-based recommendation engine, we will see what is a graph database and how it can help overcome shortcomings to design a robust, scalable, and fast recommendation engine.
Graph Database
A graph database is a database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model.
A graph database management system is an online database management system with Create, Read, Update, and Delete (CRUD) methods that expose a graph data model. In a graph data model, they don’t have to infer data connections using things like foreign keys.
Relationships can also be modeled by relational databases; but to traverse those relationships, we need to write SQL queries that JOIN tables together. The joining process is computationally expensive and becomes slower as the number of joins increases, which makes real-time analysis impractical in production.
The graph database that we used is Neo4j. Neo4j is a native graph database platform, built from the ground up to leverage not only data but also data relationships. Neo4j connects data as it’s stored, enabling queries never before imagined, at speeds never thought possible.
Since relationships are made explicit by the edge elements, traversing the graph is both simple and inexpensive. As a result, relationship-based queries in real-time can be easily performed, we can quickly capture any new movies searched by users and interests shown in their current online visit, both of which are essential for making real-time recommendations.
Graph databases use Nodes and relationships to store data so we have to define nodes and relationships.
Nodes are the entities in the graph. They can hold any number of attributes (key-value pairs) called properties.
Relationships provide directed, named, semantically relevant connections between two node entities (e.g., Employee WORKS_FOR Company). A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can also have properties.
Data
The data used comes from various open sources consisting of millions of users and movies, shows, etc.
User data contains information like unique user ID, favorite genres, watched movies, and rated movies by the user.
Movie data consists of movie name, id, genres, actors, directors, image URL, etc.
Based on the movie/show name external APIs have been used to collect data related to movies/shows like IMDB ratings, directors, writers, and producers to enrich the data.
Data Sources
https://developers.themoviedb.org/
Data Pre-processing
Before storing data in the graph database some pre-processing steps have been performed-
- Users who didn’t give any kind of rating have been excluded.
- Movies whose partial information is missing, are extracted using APIs.
- Average ratings for a movie have been calculated.
- Mapping of genres.
- A similarity matrix between movies has been calculated.
Following nodes and relationships between them is created and schema is designed-
Nodes-
- Users- It consists of unique userId
- Movies/Shows – Unique Id
- Genres – Genre name
- Directors – Director name
- Actors – Actor name
Relationships-
- User-movies: the relationship between user and movie
- User-Genres: the relationship between the user and favorite genres
- Movie-genres: the relationship between movies and associated genres
- Movies-movies: similar movies based on genres
- Director-movies: movies directed by directors
Graph-based recommendation engine-
In this section, we will generate recommendations from Neo4j using Cypher query language which is a declarative graph query language that allows for expressive and efficient querying and updating of a property graph. Further details about
First, just quickly explore how the database schema looks like in Neo4j.
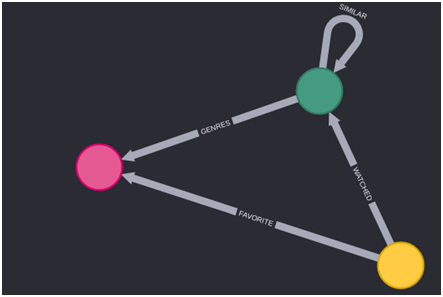
In the above figure, some of the nodes and relationships have opted out. Here nodes are represented in different colors e.g. – the yellow node denotes Users; the pink node denotes movie genres and the green node denotes movies and different relationships between different nodes.
Let’s explore movies watched by a user-
//Movies watched by a user
MATCH path = (u:Users)-[:WATCHED]->(m1:Movies)
WHERE u.userId =~'1'
RETURN u.userId, m1.title, m1.rating_mean
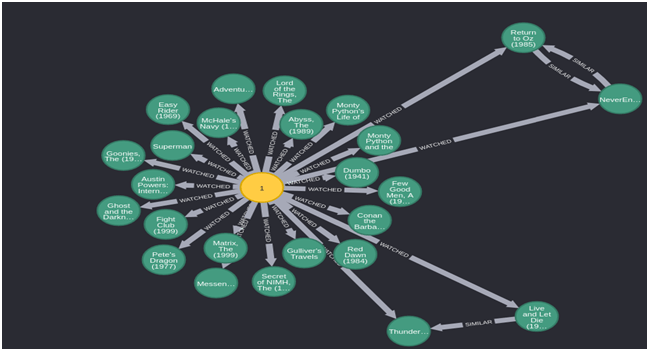
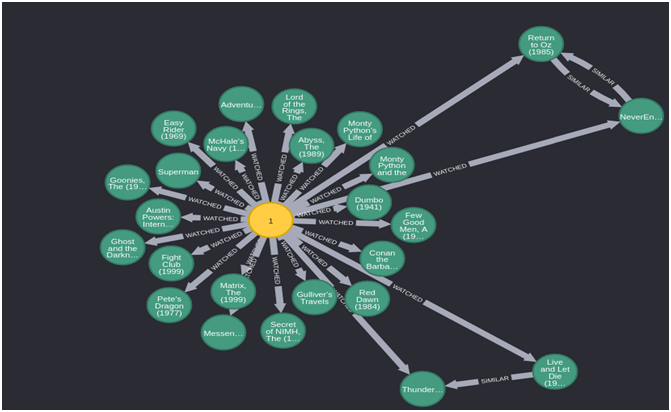
In the above graph, we can see how easy it is to query movies watched by a user. Along with movies, we can also see that similar movies that are watched by a user can be fetched. So, we can see graph database is capable of storing such types of relationships which makes it easy to make real-time recommendations.
This is not a schema or ER diagram but represents actual movies watched by a user.
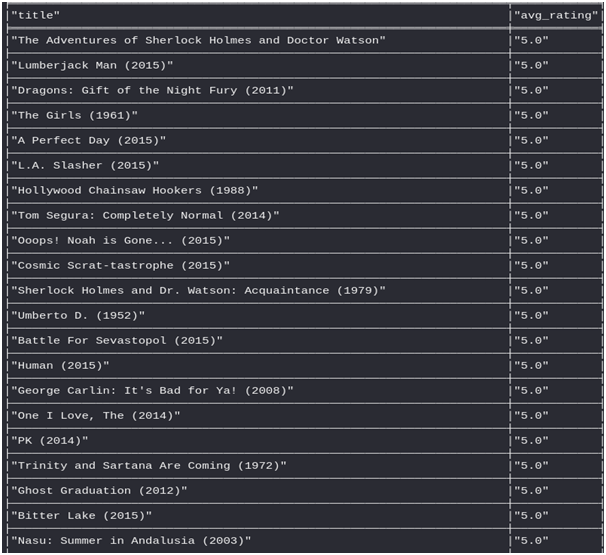
Now we have a graph for a user we can easily think of generating a recommendation for a user. The simplest way to recommend movies for a user is to recommend the most-rated movies of all time.
MATCH (u:Users)-[:WATCHED]->(m2:Movies)
WITH m2 ORDER BY m2.rating_mean
RETURN m2.title AS title, m2.rating_mean AS avg_rating
ORDER BY m2.rating_mean DESC LIMIT 100;
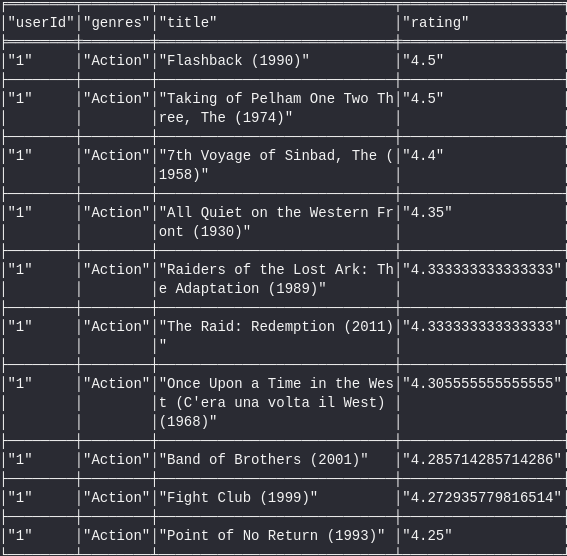
Recommendation based on Similar users
Recommended movies-
//Movies based on similar users
MATCH (u1:Users)-[:WATCHED]->(m3:Movies)
WHERE u1.userId =~'1'
WITH [i in m3.movieId | i] as movies
MATCH path = (u:Users)-[:WATCHED]->(m1:Movies)-[s:SIMILAR]->(m2:Movies),
(m2)-[:GENRES]->(g:Genres),
(u)-[:FAVORITE]->(g)
WHERE u.userId =~'10' and not m2.movieId in movies
RETURN distinct u.userId as userId, g.genres as genres,
m2.title as title, m2.rating_mean as rating
ORDER BY m2.rating_mean descending
LIMIT 10
Recommendation using Item-item Similarity-
// Item-Item Similarity
MATCH (m2:Movies {movieId: "10"})-[:GENRES]->(g:Genres)<-[:GENRES]-(other:Movies)
WITH m2, other, COUNT(g) AS intersection, COLLECT(g.genres) AS i
MATCH (m2)-[:GENRES]->(m2g:Genres)
WITH m2,other, intersection,i, COLLECT(m2g.genres) AS s1
MATCH (other)-[:GENRES]->(og:Genres)
WITH m2,other,intersection,i, s1, COLLECT(og.genres) AS s2
WITH m2,other,intersection,s1,s2
WITH m2,other,intersection,s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2
A user has watched movie GoldenEye based on the genre similar movies recommended are –

Conclusion
- Neo4j database is fast to query in real-time.
- Neo4j combines graph-based queries and algorithms for scoring recommendations and enables creation of weighted scores based on multiple techniques in real-time – resulting in more accurate, context-aware recommendations.
- When making recommendations, time is of the essence. The speed and flexibility of graph technology enable us to offer real-time recommendations by reducing recommendation calculations from minutes to milliseconds.
Some other ways to design a recommendation system-
https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e
Similarly, we can use graph databases in various use cases like fraud detection, feature engineering, link prediction etc.


