We’ve been encountering resource shortages in one of our environments, which has led to delays in processing. This issue arises from sudden spikes in load on our RabbitMQ queues, necessitating an increase in workers to handle the queue consumption.
Our project is centered around Microservices-based architecture and leverages various services, including Celery, RabbitMQ, Redis, MinIO, MongoDB, and Postgres.
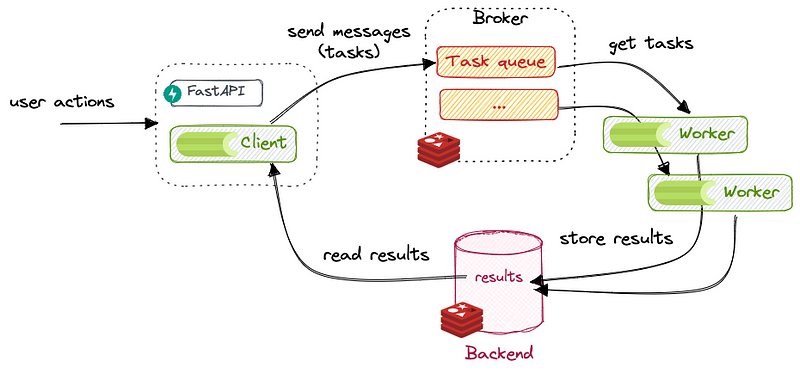
As the number of task elements queued in RabbitMQ grows, a single worker can’t handle the increased load, which also impacts the resource consumption of individual workers. To address these issues, we use Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA).
Previously, this process required significant manual intervention. Developers had to continuously monitor resource usage and manually scale up workers whenever the load increased. This approach was time-consuming and inefficient, diverting valuable developer time and attention from other critical tasks.
To address these challenges, we turned to Kubernetes’ autoscaling capabilities. By implementing both Vertical Pod Autoscaling (VPA) and Horizontal Pod Autoscaling (HPA), we aimed to create a more resilient and responsive system. VPA adjusts the resource limits of our pods based on actual usage, ensuring that each pod has the necessary CPU and memory to perform efficiently. Meanwhile, HPA dynamically scales the number of pod replicas based on metrics such as CPU utilization or custom metrics like RabbitMQ queue length.
This dual approach allowed us to handle varying loads more effectively, reduce manual intervention, and improve overall system performance.
Implementing Vertical Pod Autoscaling (VPA)
Vertical Pod Autoscaling (VPA) involves monitoring the resource usage of a pod, specifically CPU and memory. To implement VPA, we utilize Kubernetes’ native toolset, which includes the installation of Custom Resource Definitions (CRDs) and several deployments. These components work together to monitor resource usage and automatically adjust the resource limits of your pods, ensuring they have the appropriate amount of CPU and memory based on actual demand. This helps maintain optimal performance and resource efficiency within your Kubernetes environment.
Installation of CRDs: https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
The above link will help you install the perquisites of Vertical Pod Autoscaling.
Once you have installed the CRDs, you will now need three major deployments necessary for enabling vertical pod monitoring and autoscaling.
The three deployments are:
- VPA Admission Controller
- VPA Recommender
- VPA Updater
Recommender – it monitors the current and past resource consumption and, based on it, provides recommended values for the containers’ cpu and memory requests.
Updater – it checks which of the managed pods have correct resources set and, if not, kills them so that they can be recreated by their controllers with the updated requests.
Admission Plugin – it sets the correct resource requests on new pods (either just created or recreated by their controller due to Updater’s activity).
For installing these deployments, you can install the project that is mentioned in the above link, or you can use these YAML files.
VPA Admission Controller Yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-admission-controller
namespace: kube-system
labels:
app: vpa-admission-controller
spec:
replicas: 1
selector:
matchLabels:
app: vpa-admission-controller
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: vpa-admission-controller
spec:
containers:
- name: admission-controller
image: registry.k8s.io/autoscaling/vpa-admission-controller:1.1.2
imagePullPolicy: Always
ports:
- containerPort: 8000
protocol: TCP
- containerPort: 8944
name: prometheus
protocol: TCP
resources:
limits:
cpu: 200m
memory: 500Mi
requests:
cpu: 50m
memory: 200Mi
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- mountPath: /etc/tls-certs
name: tls-certs
readOnly: true
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: vpa-admission-controller
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes:
- name: tls-certs
secret:
secretName: vpa-tls-certs
VPA Recommender
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-recommender
namespace: kube-system
labels:
app: vpa-recommender
spec:
replicas: 1
selector:
matchLabels:
app: vpa-recommender
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: vpa-recommender
spec:
containers:
- name: recommender
image: registry.k8s.io/autoscaling/vpa-recommender:1.1.2
imagePullPolicy: Always
ports:
- containerPort: 8942
name: prometheus
protocol: TCP
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 50m
memory: 500Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: vpa-recommender
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
VPA Updater
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-updater
namespace: kube-system
labels:
app: vpa-updater
spec:
replicas: 1
selector:
matchLabels:
app: vpa-updater
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: vpa-updater
spec:
containers:
- name: updater
image: registry.k8s.io/autoscaling/vpa-updater:1.1.2
imagePullPolicy: Always
ports:
- containerPort: 8943
name: prometheus
protocol: TCP
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 50m
memory: 500Mi
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
securityContext:
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: vpa-updater
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
Once you’ll add these deployments, you will need a secret called vpa-tls-cert.yaml file that is being used in the secrets of one of the deployment.
Vpa-tls-cert.yaml
apiVersion: v1
data:
caCert.pem: >-
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURNRENDQWhpZ0F3SUJBZ0lVWmQvQzNURmNrbXM5eXpRMEowK2E3VVRkK0ZFd0RRWUpLb1pJaHZjTkFRRUwKQlFBd0dURVhNQlVHQTFVRUF3d09kbkJoWDNkbFltaHZiMnRmWTJFd0lCY05NalF3TlRJME1USXdPVFEwV2hnUApNakk1T0RBek1Ea3hNakE1TkRSYU1Ca3hGekFWQmdOVkJBTU1Eblp3WVY5M1pXSm9iMjlyWDJOaE1JSUJJakFOCkJna3Foa2lHOXcwQkFRRUZBQU9DQVE4QU1JSUJDZ0tDQVFFQXBaQjRVaHdRTXBIY25NYURvbkdLVjlnOGJrSGUKSkNVSzc0T2drTVNiL01HNUZ1T1RLRDhMaituUnZ1S3F4Sm1yaXJkTzBoRGxyR1FzSXMrM2RNaUZYS2YrYldBbwplcXNIY1o4L2hSZ1Q3SU1yNzUvbG0weTV5RGIvcHhaMS92WkNhUldoUUNEVk04bG85d0dEeTdsbWt0b0R5Q0YwCk5CNVlINjdQR3g0Y2RSa3d1S2V5ZVYyclVETmNBaDhFTnBoNWsxeW4rckFreG5xa3N5YS9iSCtUWDR0ZmZwZEMKYlNqY0pGSXlPLzRmYjRtd256NWhvSlBEdTV3aFVtc3J6UTZjQ3NRT2dpZStzWlZHaW1GZnZBWG85L2xKSGpydwppWVlKV3BJWUl1OTZWSnl0Sk5vK2hzRFdGTThCZ05LRnVOUXdjSk4yT1VxVFhtSDM1OU11cXd1NElRSURBUUFCCm8yNHdiREFkQmdOVkhRNEVGZ1FVcVF2bHJqd08zUUtPeHhvY1pnamIreW1Ja2tvd0h3WURWUjBqQkJnd0ZvQVUKcVF2bHJqd08zUUtPeHhvY1pnamIreW1Ja2tvd0R3WURWUjBUQVFIL0JBVXdBd0VCL3pBWkJnTlZIUkVFRWpBUQpnZzUyY0dGZmQyVmlhRzl2YTE5allUQU5CZ2txaGtpRzl3MEJBUXNGQUFPQ0FRRUFtNm9mQ0ZPN3NiMjhLdnZ2CmZBUVVlNDJnR3NZWGpCSG1ydjlIY2dqUFRVZmZRd25NSHpJblNydWRmVUZBTXNQRkw1Mm1WemVISnQ5cEkzUnMKYVJwSkF4MmRvS3pJMS9RaUxsc1RQWEp2aFJSK1RFc2wva0dxU0taQ3V3OFNIRGdhR1R0cFA1aEZkOWdIUUVrUApUYlc2NWRjd251ZG1md3RLZW15dFZUbnkxRjB5M2lHc3hwTlA1TkM0TzNVVG1pc3p4bTVkbjlOay9ncnc1dHV5Cm1IZi8ya2FUcy9Na3BoNEpGS1preVpyUTM2T2YyeE9DdUhMV1o5dzFhL0c1WGVCUHM0K1piNEhMbFJreW4xWWIKZXE3YWRGbHlmVzFJcDNVZHNVckZUbnA5WG1LY3BrVElWSWtlMU1uRDArclZMZElHOTRTeW1Za1FnRkFycWdhZQo3MXNIdnc9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
caKey.pem: >-
LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcFFJQkFBS0NBUUVBcFpCNFVod1FNcEhjbk1hRG9uR0tWOWc4YmtIZUpDVUs3NE9na01TYi9NRzVGdU9UCktEOExqK25SdnVLcXhKbXJpcmRPMGhEbHJHUXNJcyszZE1pRlhLZitiV0FvZXFzSGNaOC9oUmdUN0lNcjc1L2wKbTB5NXlEYi9weFoxL3ZaQ2FSV2hRQ0RWTThsbzl3R0R5N2xta3RvRHlDRjBOQjVZSDY3UEd4NGNkUmt3dUtleQplVjJyVUROY0FoOEVOcGg1azF5bityQWt4bnFrc3lhL2JIK1RYNHRmZnBkQ2JTamNKRkl5Ty80ZmI0bXduejVoCm9KUER1NXdoVW1zcnpRNmNDc1FPZ2llK3NaVkdpbUZmdkFYbzkvbEpIanJ3aVlZSldwSVlJdTk2Vkp5dEpObysKaHNEV0ZNOEJnTktGdU5Rd2NKTjJPVXFUWG1IMzU5TXVxd3U0SVFJREFRQUJBb0lCQUhRbnpuSjA0OXhHdjB0eQpic25aOUtBNndmTHMzVWZvZ1NxVzQyQ052NDV0NzBnaXM0eUo1cmU1NklDT2tCWk1aYkIxZUtRaVhMQTh1MFpWCkNyV3hOUGRUbVVudEs1a2NRcVd4ZnlRR1Izd29idnUzNTZPMENhZHhCcDJZUVlKMkRST2lyRFhNa3llNUI1NDcKL3RaQUpibWpvUUdZanVrOTNMK2xxZ0d4ZDIraThsV1I0SXliWHMrYzdjZmdXd0ZyRmJLVnJEVUxDNXlsck13awp0RHZkNjZXdUJ1aEY1Y2RCRE9LTjlaZ1JnUHFEVlRqYUZNUTkyWHdoNEE1Q1JGZzRCK21sUmFRQ2NaZHdEZWJXCktGNGJBUjh0RDNYdjB4UUxBb0pCVkROaWRoSEQ3cERmZVdOQ0pMZTZjc0ZEUjZyeHpFcWJtMWpKTEFYNFBLMHEKUFM0MFdpMENnWUVBMmZqZnpDN1hwTk9jVXJaWFN1VmVxd2dkdHludG83QmJZdFdieVpxdnRaNklEVEpCeWp6TQpjU1VyYStLUmExZjBMYXlwaFhwOVBvUnZLRXI2ZHJXditNMHJQc01NeHVaQWFYMDg0b3hPakovK0NDMmMwa1JEClEzNldhMkUvMEpFb1A0VllwalFaWUFMbjl2UThuUWJLOWJDcG1jUkFTL3pKNWJPMjJ0NjJ3VzhDZ1lFQXduTHgKMFkzWUFMRFVBYlBpcCtMSjd1VDZ1RmZnY3hjOVY4MnFsVC9LZzBOdHJHMXB1dk41RXc1ZWQrQ051RlEvcERWVwpWS0N5bnAyaHJ0OFBvcjRwTkFFUUxzT3FOTks0ellqYm1hK3dhcHpqRkpxV3IybGczbjdEVlFicGVlbTBqa3BLCm5LZjBiNFJ6NFd2MndVVFdyRVM0eXZIRUpmMlhEZDZlUVRBeE4yOENnWUVBbXZQR1BNT3IvdnVEckhUOWR6dTUKWWNKaVJYeGorREo5dExQL2pJRVBtZi81M2MrMVgweDdWWS9EMzJ6d1RhdjM1S1JTMnBXcUJWQm1LUEdzUGNtSgpNRWpDRGxyZ2NXRHJ0MUlWZjBPWTczVXBSSzBRUjVYSmIyakZDODdWYTdKVk4xclhHMGY4SmZuSzV3N1hMQlhSCklIbVhCNzJ3cTVRbi9zZ1VIR0dvNzdjQ2dZRUFnSFd2aStGSmNpdGY1RUFTM1JiV2tSeDFCcFFIbEFFbVpYdFoKMW4vdUtnbkJ5c2Y5c2FSbnVFOGwyY3hmMUFiVWhJYzRJWENJa0lGUzcxUXQ0RFlBd25weFZuT3RYbmhYM25FcgpvcnlPcitBMXBNYjhCYVo0ZUlVR1JvWHFlTUFNcUhRc0ZwSmV5YzJYUUxVeXJ6dnJGcVBQOFVNSGNwRzEyVlBZCitQZjlpOEVDZ1lFQXpIRTFya1dSSG9XYnVjbGRXZWx1OGo1Q2o2NXJNVzVqU3poQklNR1IrZGErQ2lLR21GUGEKM1FSZnhkcHAwWGk2UlM1TGMrRndjQTFXQ1J4TmdYT0UrcGFoL3FFSG42NHJickV1MnlZVTFFTWwyT2haS3Z0QwpFS1p0YjFLcHFUaXhaZjFwMjdCRzY2cnptd0RpSUpTeExQSEh3VE55eHI5VUlYbksyZ1M4eCt3PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
serverCert.pem: >-
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURNRENDQWhpZ0F3SUJBZ0lVTWlKRDEwRVdZUGVUMk5wbFJLdlcvbE05R1Uwd0RRWUpLb1pJaHZjTkFRRUwKQlFBd0dURVhNQlVHQTFVRUF3d09kbkJoWDNkbFltaHZiMnRmWTJFd0lCY05NalF3TlRJME1USXdPVFEwV2hnUApNakk1T0RBek1Ea3hNakE1TkRSYU1DWXhKREFpQmdOVkJBTU1HM1p3WVMxM1pXSm9iMjlyTG10MVltVXRjM2x6CmRHVnRMbk4yWXpDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBSnFIbUNEVkplbjAKNXpSNlhKaGVJYWFBcnRGVUswa2hRYmNRTDYzelhkRzhndXpkRzF0azlRNW13UGp1OGtNKytwelZDeGhHc2hpSQpmUVJSVklGN1g2R1FydXNsS3A4a011OWhPaGFiTHNtSEpiNll2MmpydjdQSkljMFlrTmwzNHNyeWNIZFNPNjJICmh0eU9qVHprdWExT21YbGF2QzR0YzlkTU5uTTVVbE02eVhSc2FId08rOWJPZ0RuNmR0ZWJPNkhFaXoxdFVrZVMKL2VVNS9OZ3laeDhIUUUvNFpPd2tqUFhkYjFOL0lPaHBxUktqTHY0MVRFNTBMOUtzYStVRzJ4Mnk1aUZ1bXJoZQpjKzdNUmllbmxlcnJRQmcyaU5qOVNVQTdoNGhxOWRwWWIrVHREdENzKzdEczltSFZ5S3hWUktrREdkZDVoK2U5CjFzTCtzclJVNkRrQ0F3RUFBYU5oTUY4d0NRWURWUjBUQkFJd0FEQUxCZ05WSFE4RUJBTUNCZUF3SFFZRFZSMGwKQkJZd0ZBWUlLd1lCQlFVSEF3SUdDQ3NHQVFVRkJ3TUJNQ1lHQTFVZEVRUWZNQjJDRzNad1lTMTNaV0pvYjI5cgpMbXQxWW1VdGMzbHpkR1Z0TG5OMll6QU5CZ2txaGtpRzl3MEJBUXNGQUFPQ0FRRUFOUW9LSTNBRWUvdEdtUUhlCmxFZi92K0sxRnF1QUZrYXFDS0dYM08vcXJCVXBvdXFoY2RmMXNKSzRnRXFlejJWbEVhNmJucnAwYVBoYTNGMzgKS3VOWmNUNXJJNnl2bVZ4cWtCbTczTHUxUjNFQ2NCYk5xaDRjczd1SjZsYUV0OE0reGpuUEZ3WnV5a0NQM0t4SgpMQkJTSWRpMy9rYTMxTVdQV0JsYzdCSklvUFNtOGQ0RDh1NDVMYTJyaGtYMWVSNUluZ0lMMCtVdXFzY3pXUkdHClV4a2t2bEUwYUpBN0hzVEc1azVweHJWZ1VhdUM0VjA5enNPTkYzdHFmYWtYSmU0UUlLWmtTdEJ4bXVPRU9uWXMKUElzVHR1bEFKM3ExbHdITDh4V0RnakZZVmNHRFZBOFFHd2Y1dGJhek9RZXRyb0F2Qy83Q0hscFIxMjhxWEcrMAppbitHSXc9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==
serverKey.pem: >-
LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFb3dJQkFBS0NBUUVBbW9lWUlOVWw2ZlRuTkhwY21GNGhwb0N1MFZRclNTRkJ0eEF2cmZOZDBieUM3TjBiClcyVDFEbWJBK083eVF6NzZuTlVMR0VheUdJaDlCRkZVZ1h0Zm9aQ3U2eVVxbnlReTcyRTZGcHN1eVljbHZwaS8KYU91L3M4a2h6UmlRMlhmaXl2SndkMUk3clllRzNJNk5QT1M1clU2WmVWcThMaTF6MTB3MmN6bFNVenJKZEd4bwpmQTc3MXM2QU9mcDIxNXM3b2NTTFBXMVNSNUw5NVRuODJESm5Id2RBVC9oazdDU005ZDF2VTM4ZzZHbXBFcU11Ci9qVk1UblF2MHF4cjVRYmJIYkxtSVc2YXVGNXo3c3hHSjZlVjZ1dEFHRGFJMlAxSlFEdUhpR3IxMmxodjVPME8KMEt6N3NPejJZZFhJckZWRXFRTVoxM21INTczV3d2Nnl0RlRvT1FJREFRQUJBb0lCQUV3WXM4aVBUa0ZjMGJKZApBMVloSEs4U3RZUHR6L2NPUW44MG9GWW4veTUyaDM2L0QyYTlXNVFBODh4aVZyall2YThYbG9RWTVFRUNqWlhmCnV4NmNNNmFyU2dnUDRHSklBREV6anRodENPaEMva3BTakFmTitEUS91cjUxOTNhdisrWDI1MzFLNklwMnIrblMKNVNoMGRoOHJFcGJaSU13WW8vQUUzdGQxQmQ1bjA4STk5RzlCWktBNmdjL2ZJNEJPVk5lamVWcVEyUUNHOEovVQpRZnd5bG94Z3F0bE1vWklVNW0weS8vQWN6bTg5dGtQcjZnS3psMmh5VXN2eGNjdXBCSzMwWXhvRUUzZ0FudWxjCk44SkdSYitUZmQwYUxEOXhxdHc2aDRHcE9paDdvNkFoNURmcm5PUVlVSytwK1piK0NhMW9RNHJSYVRFekR5YUgKOExHVlVqVUNnWUVBeDdYUDVLaklCOURESkIvYWp6emVZejVBZGVhakdZSmlVOHNPSWxnSGFaK05hWE1qYXlQbQpzRCtLWXZzeEhGNW85VWlQalJKckN3ZDBPaTdvSXFuYVRwRHJmcE5VdWppWURkeXp6VkM2Zmw3NGxJZDBmdzloCkNta0JWVk81VjBUbjF2dnNDam1hM05FNmY0dUpPNm8vTlp5S2MxTVV0OCtZQ1d0NGtuLzBNZmNDZ1lFQXhoWEMKR2RMdDlCVUhDVTBwWDNsb1NSVmpVS0lDdGhjVGN0RFVkdXdyZ2dIOEhERUJpRm9wTjl5ZVNRYS9JTjF6SFRxUQpTQmt5cHNkelBQVUlFZUx2c0lQckFSMGlxWUR3dWU1d1VsVUdyblhjeUFtdGxmNlZSVUpCVUVLSnNJZHF4aXlCCkJPU2VXWXNyS2d0ZWRjSTk1ODNRZGpOaG5iWVdFOVR3OU9QVEswOENnWUJRUS81K1JHZkEzR0xSemd1bHJpMGoKYmcyeVZUUVFPSnNVV25RZjBZbUpKaHRMMm43TnZPd213aUw0alVTN3hpWWhEenpDMGpnN2dvOXdJeEloZkdyRgpVUEdWT2RtL3pxY3VTeG5vMXgxZFZRWkxpL1dDYThmd3l5dENCQmhsdnNmL1c5a09jd0NPNTNpL2NuR0JqWGRDCk1OeGtaV3ZhUkpFeW1BTXB2a3VER1FLQmdRQ2NmSWZ3MnIvOWViY3JVL2dCWXVwT0FrV0paOVA0Z2xacytDbEIKSWVabE9LZ3dwVTV1cDd1MFUrZ0FEUUpsTmsxQXBBbGp5L1JGNlg5U2dza3pTRExQSWdnL3d3S2xJaVlLM1NHRApDWVRUd216KzR4WnRUc2dpQk91UU9tQ0lReExKS0ZOc3lDZUkyZmJwcWoyZmppcFZ2RFNaakpIcmcvUUJDdEtvCnhHc0k1UUtCZ0J3UXB4T1RpNlc4OFZGZGYyRDBZTzJGYUNqV3E4Kzk1SzdUK3Q1YU9CTlhsMzJwd3JzNVI3aGMKUnFEVklZTG9MNWZHVEgyZDcvdmNXS1dwMjFCTDNvZjZldlNXNEFQNnJ0NlRUTFdBYkFjbmRTMlNlOWkrMTVlUgpTQlZibEU3VFA5ajg5UEdDc1F5STNZeWJrMWN6NERrTjJ0MHplU25WVG5aeHR3ZWdWNVVxCi0tLS0tRU5EIFJTQSBQUklWQVRFIEtFWS0tLS0tCg==
kind: Secret
metadata:
creationTimestamp: '2024-05-24T12:09:44Z'
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:caCert.pem: {}
f:caKey.pem: {}
f:serverCert.pem: {}
f:serverKey.pem: {}
f:type: {}
manager: kubectl-create
operation: Update
time: '2024-05-24T12:09:44Z'
name: vpa-tls-certs
namespace: kube-system
resourceVersion: '60147243'
uid: 51ac2807-1af8-4822-b828-0f9876f5c6a6
Now, the installation part is complete here. The thing you will need now is VPA YAML for your deployment.
Example-vpa.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: pod-name-vpa
namespace: default
spec:
resourcePolicy:
containerPolicies:
- containerName: '*'
controlledResources:
- cpu
- memory
minAllowed:
cpu: 50m
memory: 100Mi
maxAllowed:
cpu: 2000m
memory: 4096Mi
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: pod-name
updatePolicy:
updateMode: "Off"
In the above example, we have set the minimum allowed and maximum allowed resource usage to the pod.
The VPA will now monitor the pod with this given minimum allowed resources, now there is this key call updatePolicy that consists of different update modes.
Modes:
- “Auto”: VPA assigns resource requests on pod creation as well as updates them on existing pods using the preferred update mechanism. Currently, this is equivalent to “Recreate” (see below). Once restart free (“in-place”) update of pod requests is available, it may be used as the preferred update mechanism by the “Auto” mode.
- “Recreate”: VPA assigns resource requests on pod creation as well as updates them on existing pods by evicting them when the requested resources differ significantly from the new recommendation (respecting the Pod Disruption Budget, if defined). This mode should be used rarely, only if you need to ensure that the pods are restarted whenever the resource request changes. Otherwise, prefer the “Auto” mode which may take advantage of restart-free updates once they are available.
- “Initial”: VPA only assigns resource requests on pod creation and never changes them later.
- “Off”: VPA does not automatically change the resource requirements of the pods. The recommendations are calculated and can be inspected in the VPA object.
The preferred way to monitor usage would be in the “off” mode, which keeps track of the resource usage and doesn’t automatically change the resources.
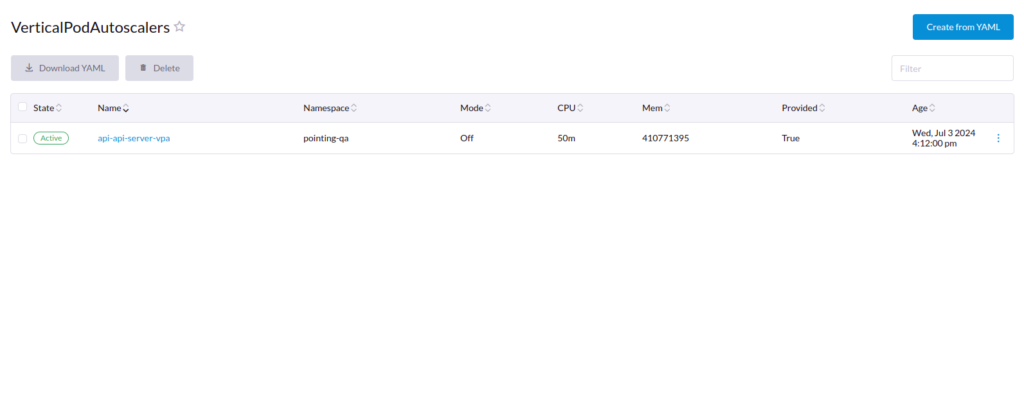
In the above Image, the recommendations are updated by the VPA. As you can see in the example vpa yaml file, we set the minimum allowed resources, and the recommendations are updated based on that, the memory is in Bytes value.
As soon as you’re convinced with the recommendations you can allocate the resources to your deployments.
Implementing Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaling (HPA) involves increasing the number of instances of your component. For example, you have a worker pod that takes one minute to complete a task. Under heavy load, where the worker has ten tasks to process simultaneously, you wouldn’t want to wait ten minutes for all tasks to complete sequentially. This is where HPA becomes crucial. By automatically increasing the number of worker pod instances, HPA ensures that multiple tasks can be processed concurrently, significantly reducing the overall processing time and improving performance under heavy loads.
In our case, we have a microservice architecture-based system that involves multiple tasks. Every task is a microservice that runs when the task is called and goes idle. This task execution is taken care of by the broker RabbitMQ.
So, to auto-scale the pods based on the number of queues in RabbitMQ, we use are using a tool called Keda.
Installation: https://keda.sh/docs/2.14/deploy/#install
In our case, we have been using the helm chart for managing our project, and we have integrated this chart to our helm.
Here is the HPA-deployment YAML file:
{{- if (($.Values.autoscale).enabled) }}
{{- range $groupName, $group := .Values.deploymentGroups }}
{{- range $componentName, $component := $group.components }}
{{- $config := deepCopy $group.config }}
{{- $config := deepCopy $component | mergeOverwrite $config }}
{{- if and $config.enabled ($config.autoscale).enabled }}
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {{$groupName}}-{{$componentName | toString | replace "_" "-"}}-scaler
namespace: {{$.Release.Namespace}}
annotations:
"helm.sh/hook": post-install,post-upgrade
"autoscaling.keda.sh/paused": "{{ $.Values.autoscale.paused }}"
spec:
scaleTargetRef:
name: {{$groupName}}-{{$componentName | toString | replace "_" "-"}}
envSourceContainerName: {{$groupName}}-{{$componentName | toString | replace "_" "-"}}
pollingInterval: {{ $.Values.autoscale.pollingInterval }}
cooldownPeriod: {{ $.Values.autoscale.cooldownPeriod }}
minReplicaCount: {{ $config.autoscale.minReplicaCount | default $.Values.autoscale.defaultMinReplicaCount}}
maxReplicaCount: {{ $config.autoscale.maxReplicaCount | default $.Values.autoscale.defaultMaxReplicaCount}}
{{ if (($config.autoscale).scaleToZero | default $.Values.autoscale.defaultScaleToZero) -}}
idleReplicaCount: 0
{{- end }}
fallback:
failureThreshold: 5
replicas: 1
advanced:
restoreToOriginalReplicaCount: true
horizontalPodAutoscalerConfig:
name: {{$groupName}}-{{$componentName | toString | replace "_" "-"}}-hpa
behavior:
scaleDown:
stabilizationWindowSeconds: {{ $.Values.autoscale.stabilizationWindowSeconds }}
triggers:
- type: rabbitmq
metadata:
mode: QueueLength
value: "{{$config.autoscale.queueLength | default $.Values.autoscale.queueLength}}"
queueName: {{$config.autoscale.queueName | default $componentName}}
authenticationRef:
name: pointing-fish-rabbitmq-auth-trigger
{{- end -}}
{{- end -}}
{{- end -}}
{{- end -}}
The above YAML is getting the keys from Values.yaml under which there is key called autoscale.
autoscale:
enabled: true
paused: "false"
stabilizationWindowSeconds: 30
cooldownPeriod: 120
pollingInterval: 15
queueLength: 20
defaultMaxReplicaCount: 10
defaultminReplicaCount: 1
defaultScaleToZero: false
Reference for understanding these keys: https://keda.sh/docs/2.14/reference/scaledobject-spec/
I will walk you through some important keys mentioned above.
- paused: “true”
This flag will pause the horizontal pod autoscaling for each deployment. Keep it default false.
- queueLength: 4
You need to set this limit for each task. For instance, if a task takes one minute to complete, you wouldn’t want to wait ten minutes for the overall processing to finish. To address this, you can configure the queueLength. In this example, let’s set it to 4. When the queue length exceeds this threshold, HPA will scale the worker by adding one replica. This means that an additional replica will be created for every multiple of this set number (in this case, 4). So, if the queue length exceeds 4, one replica will be added; if it exceeds 8, another replica will be added; and this pattern will continue as the queue length increases.
- defaultMaxReplicaCount: 10
This key takes of the maximum number of instances should be increased till.
- defaultminReplicaCount: 1
This key scales down the pod to this number when the scaling is no longer needed.
- defaultScaleToZero: false
If this flag is set to true, the pod will be scaled to the IdleReplicaCount. In some scenarios, a pod may not be in use, and we prefer not to keep it running since it still consumes resources that we do not want to waste.
- queueName: app
This is the most crucial key. It enables HPA to monitor the specified queue in RabbitMQ. By using this queue name, HPA can manage to scale up and down as needed.